
What If Debates Had Referees?
P3.2: When lies get a three-day head start—and how Olympic-style scoring could change that


Imagine if NFL referees couldn’t make calls during the game. A player commits blatant pass interference? Keep playing. Someone’s clearly offsides? Let them score. The refs take notes, and three days later they publish a detailed report about all the violations. Fans argue about whether the report is biased. Nothing changes. The game’s already over.
That would be absurd.
That’s exactly how presidential debates work.
When a candidate makes a demonstrably false claim, or dodges the question entirely, or attacks a position their opponent never took—they face zero immediate consequences. Maybe fact-checkers will write articles the next day. Maybe analysts will discuss it on cable news all week. But by then, millions of people have already heard the lie, formed their opinions, and moved on. The debate is over. The damage is done.
And yet, when we think about debates, most people don’t see this as a design failure. We see it as inevitable. “That’s just how debates are.”
But here’s what’s easy to miss: presidential debates aren’t natural phenomena. They’re designed artifacts. Someone decided they should work this way. Someone chose this format, these rules, this structure—or more accurately, chose not to build in any accountability mechanism.
Which means the same thing sports figured out decades ago—that real-time accountability produces better outcomes—could work for political discourse too.
We already know how to do this. Every Sunday, millions of Americans watch referees make split-second calls about what counts as a catch, whether a player’s feet were in bounds, if someone was offsides. Every four years, we watch Olympic judges hold up scorecards evaluating gymnastics routines and figure skating performances, accepting that multiple judges with disclosed expertise can evaluate both technical precision and artistic merit. We’ve built elaborate systems—with instant replay, challenge flags, clear scoring rubrics, and transparent judging panels—that filter out invalid plays and score complex performances in real time. We understand that fair evaluation requires transparency, expertise, and accountability. We accept that in a fair competition, accuracy matters more than entertainment.
The question isn’t whether we can build information filters into our political discourse. We already have the technology, the expertise, and the cultural acceptance of real-time evaluation.
The question is: why haven’t we?
Because we’ve never thought of debates as systems that need immune responses. We treat them as performances to be judged afterward, not as information flows that need filtering in real-time. We’ve accepted that lies get a three-day head start while fact-checkers scramble to catch up.
But what if we didn’t accept that? What if we designed debates the way we design any other high-stakes information system—with built-in filters at the point of entry?
The Missing Immune System
In sports, the referee IS the immune system of the game—stopping illegal plays before they alter the outcome. Debates need the same thing.
We spend a lot of time at Statecraft talking about how healthy information systems need filtering mechanisms at multiple stages. The most critical is Stage 1: the moment information enters the system.
Think about your body. If your immune system only responded to infections after they’d spread through your bloodstream and colonized your organs, you wouldn’t survive long. You need immediate, real-time filtering. Pathogens get identified and neutralized at the point of entry, before they can do damage.
Current presidential debates have no Stage 1 filter.
A candidate can:
Dodge the question entirely
State demonstrable falsehoods
Drown substance in emotional appeals
Attack positions their opponent never took
Consume their opponent’s response time with rapid-fire claims
...and face zero immediate consequences.
The system has no immune response at the point of entry. Fact-checkers can write their analyses afterward, but by then the damage is done.
This isn’t a failure of moderators or fact-checkers. They’re doing their jobs. It’s a design failure. We’ve built a format that allows—even incentivizes—the very behaviors we all agree are destroying productive political discourse.
And we could change it.
A Thought Experiment: What If Debates Had Referees?
So what would a Stage 1 information filter look like in practice?
What I’m about to describe isn’t a formal proposal. It’s not “the answer.” It’s a thought experiment—one way to illustrate that we don’t have to accept the status quo. If you finish this thinking “I’d do it differently,” that’s perfect. The goal isn’t to get you to agree with every detail. The goal is to show you that better systems are possible.
Here’s one version of what debate reform could look like:
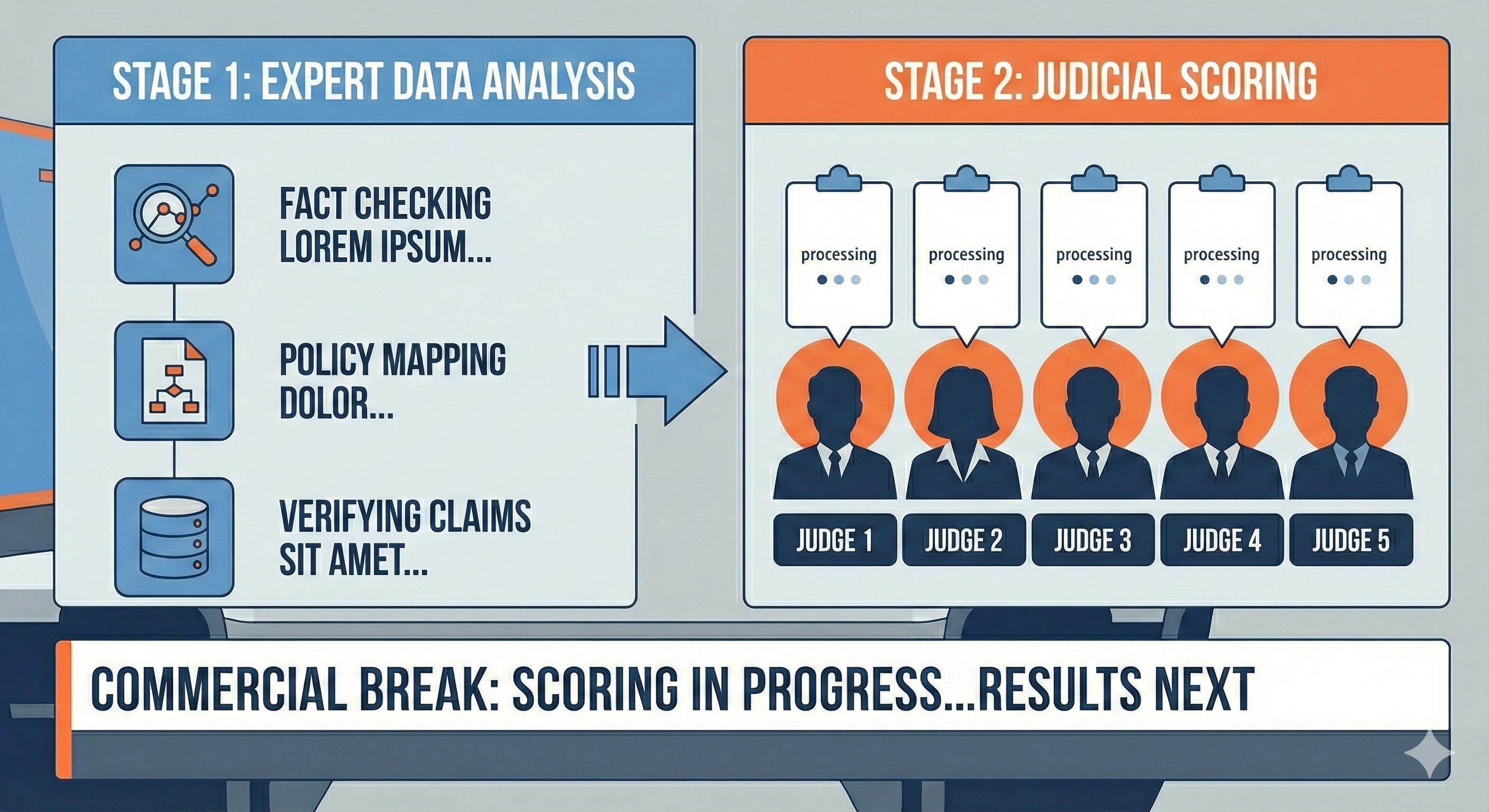
The Format
Question Phase (6.5 minutes total):
Moderator poses question to Candidate A
Candidate A responds (3 minutes)
Candidate B counters (2 minutes)
Candidate A responds to counter (1 minute)
Candidate B final word (30 seconds)
Scoring Phase (3-4 minute commercial break):
Expert analysis team uses AI-assisted transcription and pre-prepared data sources
Judges receive analysis and score the exchange
Scores compiled and justified
Like a referee’s call, this catches the obvious fouls even if it doesn’t catch every nuance—infinitely better than catching nothing in real-time
Results Phase (2 minutes):
Return from commercial
Scores displayed and explained
Move to next question

The Two-Tier Evaluation System
Here’s where it gets interesting. Instead of having commentators tell us afterward who “won,” we separate investigation from judgment—just like we do with the NTSB and FAA.
Panel members would be appointed by a bipartisan commission, similar to Federal Reserve governors, with staggered terms to prevent single-party control.
Expert Analysis Panel:
3 professional fact-checkers (disclosed credentials and affiliations)
3 policy experts with relevant domain knowledge (disclosed affiliations)
Their job: Provide objective analysis to inform the judges
Fact-check specific claims
Classify statements as specific vs. vague
Map the logical structure of arguments
Identify what each candidate actually said (vs. what opponent claimed they said)
Judicial Panel:
5-8 judges with disclosed political leanings/affiliations
Their job: Score each candidate on five criteria (1-10 scale)
Crucially: They must justify their scores, especially any deviations from expert analysis
All scores and justifications made public in real-time
The Five Scoring Categories
1. ACCURACY - Factual correctness of claims made
2. RELEVANCE - Actually answered the question asked
3. SUBSTANCE - Provided specific positions vs. empty platitudes
4. COHERENCE - Logical consistency of the argument
5. ENGAGEMENT - Directness of rebuttal (responded to opponent’s actual argument vs. strawman attacks)
Each category scored 1-10, averaged across judges, totaled to 50 points per exchange.
What This Looks Like in Practice
Let me walk you through one exchange so you can see how this would actually work:
Note: The following example uses approximate, illustrative data to demonstrate the format. The specific numbers and claims are chosen to show how the system would handle both accurate and inaccurate statements.
The Question
Moderator: “Healthcare costs have risen 40% over the past decade while median wages have only risen 15%. What specific policy would you implement in your first year to address this gap?”
Candidate A Response (3 minutes):
“Look, the American people know that healthcare costs are crushing families. I’ve talked to single mothers who have to choose between insulin and rent. That’s not the America we believe in. My opponent wants government-run healthcare that will destroy jobs and eliminate choice. But we know government doesn’t work—just look at the VA wait times. What we need is to unleash the free market, increase competition, and get government out of the way. Under my plan, we’ll allow insurance companies to compete across state lines, which economists agree will drive down costs. We’ll also expand health savings accounts so families have more control. And we need tort reform to stop frivolous lawsuits that drive up costs for everyone.”
Candidate B Counter (2 minutes):
“My opponent just said I want government-run healthcare. I’ve never proposed that. What I’ve actually proposed is a public option that competes with private insurance. And on their claim that competition across state lines will reduce costs—that’s been tried in multiple states with nearly zero impact. Georgia, Wyoming, and Kentucky all passed these laws. Total number of insurers who entered those markets? Zero. The actual problem is pharmaceutical pricing. The top 10 drugs increased in price an average of 125% in the last 8 years. I would allow Medicare to negotiate drug prices, which the Congressional Budget Office estimates would save $456 billion over 10 years.”
Candidate A Response (1 minute):
“There they go again with their government takeover schemes. Medicare negotiating prices sounds good, but it means rationing. Bureaucrats deciding which medications you can have. And those CBO numbers? They’ve been wrong before. The market works when we let it.”
Candidate B Final Word (30 seconds):
“Medicare negotiation isn’t rationing—it’s what every other developed country does and what the VA already does successfully. We negotiate prices for the military, why not for seniors?”
[COMMERCIAL BREAK - Expert Analysis & Judge Scoring Happens]
What the Judges See
During the commercial break, judges receive this analysis:
FACT-CHECK REPORT:
Candidate A claims:
✅ Healthcare costs up ~40% over decade (39.2% - accurate)
✅ Median wages up ~15% (14.7% - accurate)
❌ “Economists agree” cross-state competition reduces costs (No consensus; mixed evidence)
⚠️ VA wait times as evidence government doesn’t work (Complex - wait times actually improved under recent reforms)
Candidate B claims:
✅ Georgia, Wyoming, Kentucky passed cross-state laws (Accurate)
✅ Zero insurers entered those markets (Accurate)
✅ Top 10 drugs increased 125% in 8 years (127% - accurate)
✅ CBO estimate of $456B savings (Accurate - 2021 report)
✅ Other developed countries negotiate prices (Accurate)
✅ VA negotiates drug prices (Accurate)
POLICY EXPERT ANALYSIS:
Did they answer the question? (Asked for specific first-year policy to address the wage-cost gap)
Candidate A provided:
Cross-state insurance competition (specific policy)
HSA expansion (specific policy)
Tort reform (specific policy)
Addressed gap: Indirectly (claims these reduce costs)
Candidate B provided:
Public option (mentioned but not detailed)
Medicare drug negotiation (specific policy with CBO estimate)
Addressed gap: Directly (identified drug costs as key driver of gap)
Logical structure:
Candidate A:
Premise: Government doesn’t work (VA example)
Conclusion: Free market solutions needed
Issue: VA wait times don’t prove broader claim about all government healthcare programs
Candidate B:
Premise: Cross-state competition already failed empirically
Conclusion: Different approach needed
Logic holds: Evidence directly supports conclusion
Engagement quality:
Candidate A:
Claimed B wants “government-run healthcare”
B clarified they proposed “public option” (different policies)
Assessment: Mischaracterized opponent’s position (strawman)
Candidate B:
Directly addressed A’s cross-state claim with counter-evidence
Corrected mischaracterization of their actual position
Assessment: Engaged with opponent’s actual argument
The Scores (displayed after commercial):
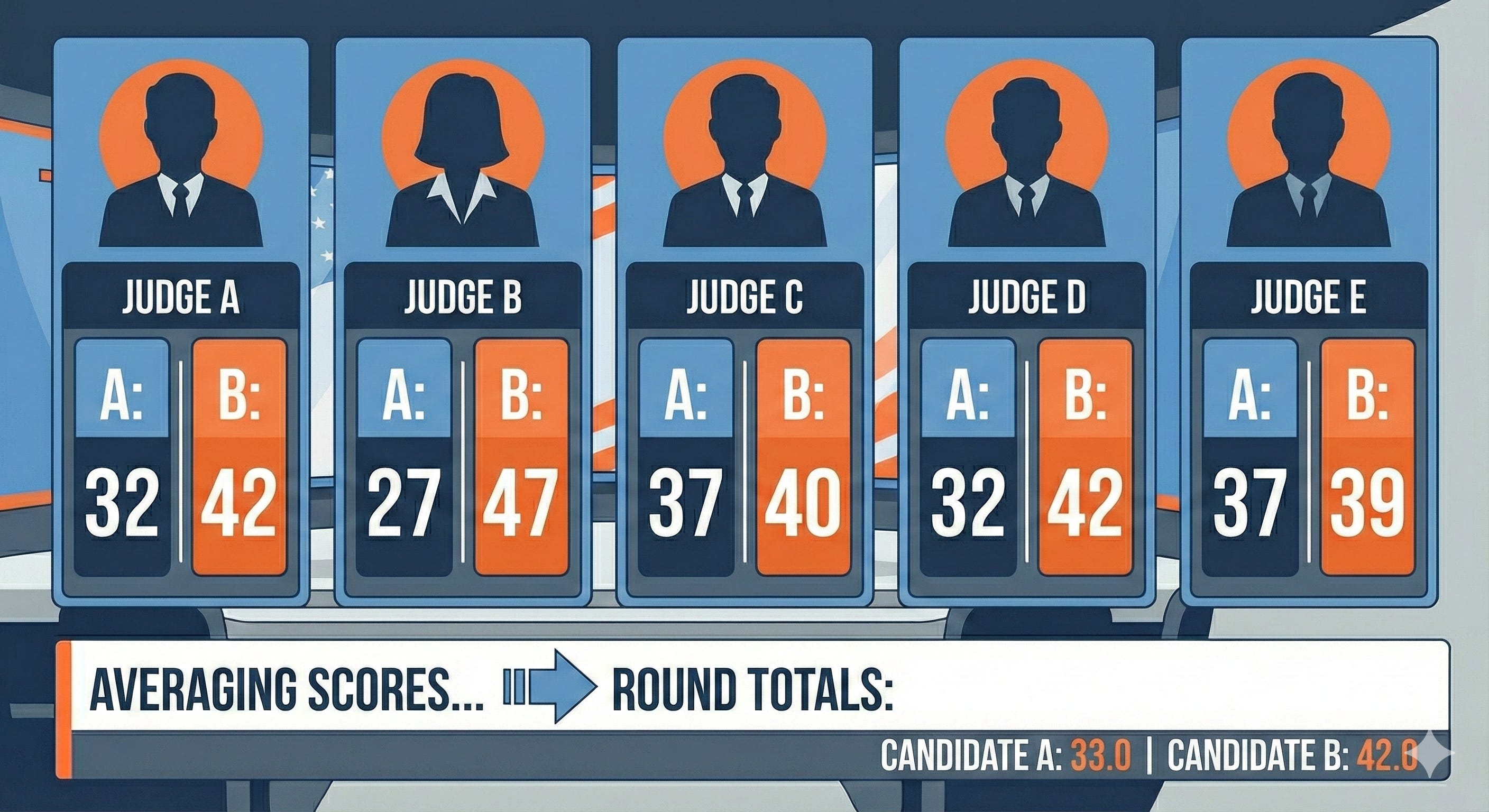
Judge 1 (Conservative):
Accuracy: A=6, B=9 (”A made unsupported consensus claim; B’s facts check out”)
Relevance: A=7, B=8 (”Both addressed costs, B more directly on the gap”)
Substance: A=8, B=8 (”Both provided specific policies”)
Coherence: A=6, B=8 (”A’s VA analogy doesn’t support conclusion; B’s logic stronger”)
Engagement: A=5, B=9 (”A conflated ‘public option’ with ‘government-run healthcare’ - these are different policies; B engaged directly with A’s actual proposals”)
A Total: 32/50 | B Total: 42/50
Judge 2 (Progressive):
Accuracy: A=5, B=10 (”A’s economist claim false; B perfect accuracy”)
Relevance: A=6, B=9 (”A more general; B specific to wage-cost gap”)
Substance: A=7, B=9 (”Both specific but B included cost savings estimate”)
Coherence: A=5, B=9 (”A’s logic flawed; B evidence-based”)
Engagement: A=4, B=10 (”Clear strawman from A”)
A Total: 27/50 | B Total: 47/50
Judge 3 (Libertarian):
Accuracy: A=7, B=9 (”Deviating from fact-check on VA - context matters for wait times, but B still more accurate overall”)
Relevance: A=8, B=7 (”A addressed market-based solutions to costs; B focused narrowly on drugs”)
Substance: A=9, B=8 (”A provided more variety of solutions; B only one detailed policy”)
Coherence: A=7, B=8 (”Both logical within their frameworks”)
Engagement: A=6, B=8 (”A mischaracterized but B could have engaged A’s actual proposals more”)
A Total: 37/50 | B Total: 40/50
Judge 4 (Moderate):
Accuracy: A=6, B=9 (”Following fact-check team assessment”)
Relevance: A=7, B=8 (”B more directly addressed the wage-cost gap”)
Substance: A=8, B=8 (”Equal specificity in proposals”)
Coherence: A=6, B=8 (”B’s logic tighter with evidence”)
Engagement: A=5, B=9 (”A misrepresented B’s public option as government-run healthcare; B engaged directly with A’s actual arguments”)
A Total: 32/50 | B Total: 42/50
Judge 5 (Conservative):
Accuracy: A=7, B=9 (”Partial deviation - while ‘economists agree’ overstates support, there is economic theory behind competition; however B’s facts clearly stronger”)
Relevance: A=8, B=7 (”A addressed systemic approach; B narrower focus on one driver”)
Substance: A=9, B=7 (”A gave three distinct policies; B focused on one”)
Coherence: A=7, B=8 (”Both coherent though B’s evidence stronger”)
Engagement: A=6, B=8 (”Public option vs. government-run is a meaningful distinction, but A could have engaged more fairly”)
A Total: 37/50 | B Total: 39/50
FINAL AVERAGED SCORES
Displayed on screen when returning from commercial:
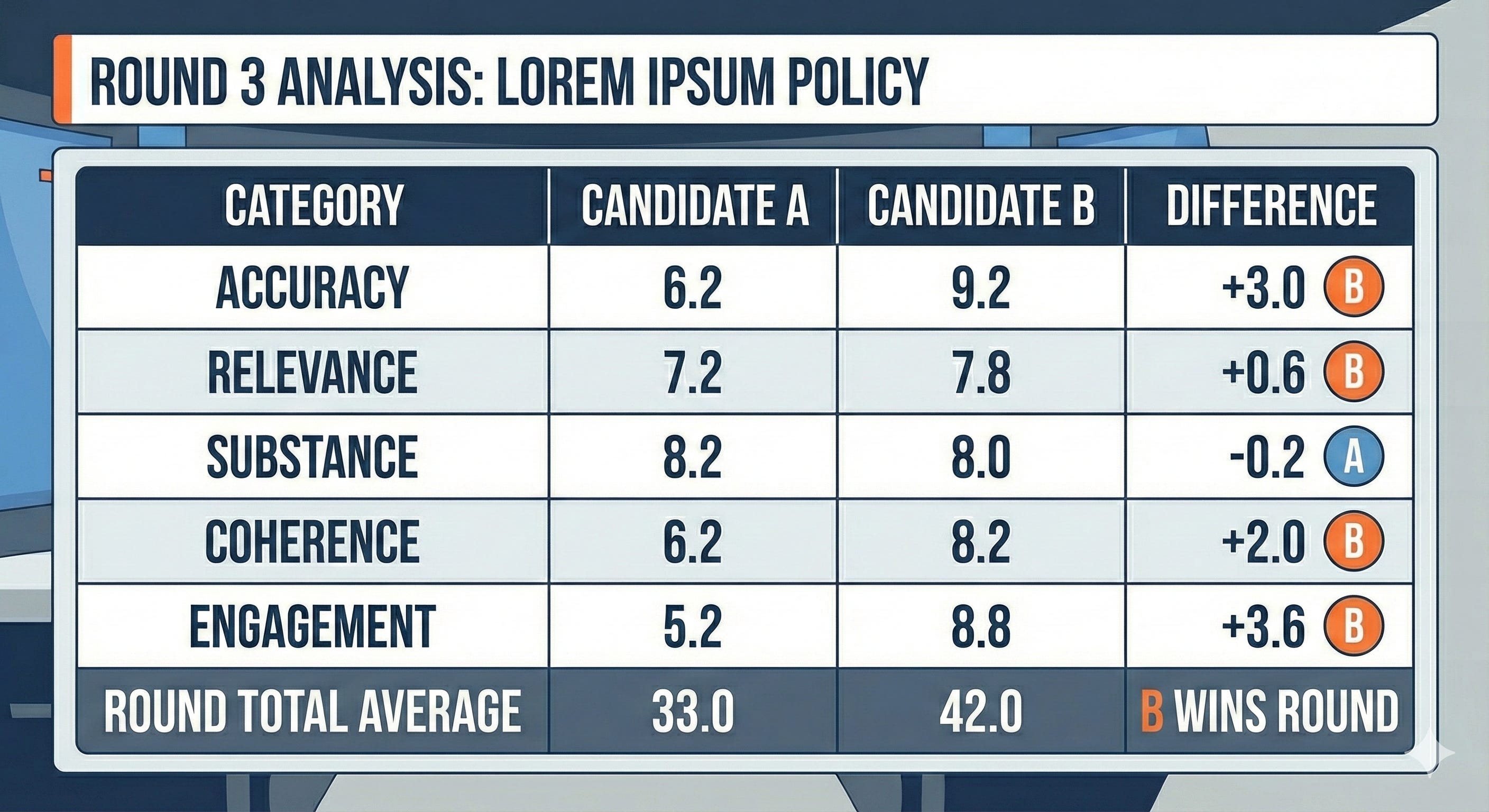
Candidate A: 33.0/50
Candidate B: 42.0/50
Category Breakdown:
Accuracy: A=6.2, B=9.2
Relevance: A=7.2, B=7.8
Substance: A=8.2, B=8.0
Coherence: A=6.2, B=8.2
Engagement: A=5.2, B=8.8
Notice what just happened:
Even judges sympathetic to Candidate A scored B higher due to accuracy issues
Judges could deviate from expert analysis, but had to justify why
Multiple judges averaged out individual bias
The substance scores were nearly equal—both candidates provided specific policies
The difference came down to accuracy, logical coherence, and fair engagement
Most importantly: All of this happened during the debate, not three days later on a fact-checking website most people will never read.
Why This Changes Everything
Here’s what just happened in that example:
You, the voter watching at home, got real information in real-time.
Not three days later when a fact-checker publishes an article you’ll never read. Not the next morning when partisan commentators tell you who “won.” Not filtered through your preferred news source’s spin.
Right there, during the debate, you saw:
Which claims were accurate and which weren’t
Who actually answered the question
Who provided substance vs. platitudes
Whose arguments held together logically
Who engaged honestly vs. who attacked strawmen
And you saw it transparently. You could see that even judges sympathetic to one candidate had to acknowledge accuracy problems. You could see where judges disagreed and why. You could see the expert analysis that informed the scores.
You didn’t have to trust anyone to tell you what happened. You watched it happen, with the receipts, in real-time.
That’s what changes everything.
Because with this system, voters get:
Immediate accountability - Lies don’t get a three-day head start
Transparent evaluation - You see how scores were determined and can judge for yourself
Objective information - Facts are facts, regardless of who states them
Informed choice - You’re making decisions based on what candidates actually said and whether it was accurate
And yes, candidates would change their behavior too:
They’d be incentivized to:
State accurate facts (accuracy scoring)
Actually answer questions (relevance scoring)
Provide specific policies (substance scoring)
Build logical arguments (coherence scoring)
Engage opponent’s real positions (engagement scoring)
They’d be penalized for:
Making false claims
Dodging questions
Speaking in platitudes
Logical contradictions
Strawman attacks
But the real power isn’t in changing candidate behavior. The real power is giving YOU better information to make better choices.
Right now, debates give you spectacle. This would give you substance.
Right now, you’re told afterward who “won.” This would let you decide for yourself, with actual data.
Right now, you have to wait and trust. This would give you transparency and truth, live, as it happens.
But What About Biased Judges? What About Elitist Experts?
Let’s be honest: some people will look at any panel of judges or experts and say “they’re all biased” or “they’re all elites who don’t represent me.”
Fair concern. Let’s talk about how this design actually addresses it.
First: Compare it to what we have now.
Right now, who decides what’s “true” after a debate?
Cable news pundits (completely undisclosed bias)
Social media (algorithmic amplification of whatever gets engagement)
Partisan commentators (explicitly biased)
Your preferred news source (selective coverage)
You have no idea who’s making those judgments, what their credentials are, what evidence they’re using, or whether they’re being honest. And even when they are being honest, it’s wrapped in sensationalism, emotional rhetoric, and spin designed to keep you watching rather than inform you.
With this system:
Every judge’s political affiliation is disclosed upfront
Every expert’s credentials and affiliations are public
Every score must be justified
Every justification is on the record
Multiple judges means no single perspective dominates
You might not like the panel. But at least you know who they are and can evaluate their reasoning.
Second: The design prevents capture.
Notice what makes this hard to game:
Multiple judges with diverse perspectives (can’t stack it all one way)
Disclosed affiliations (can’t hide bias)
Must justify deviations from expert analysis (can’t just ignore facts)
Public scoring and reasoning (can’t hide bad justifications)
Could someone still claim bias? Sure. But they’d have to explain:
Why Judge 1 (conservative) and Judge 2 (progressive) both scored accuracy the same way
Why the fact-check team’s evidence is wrong
What justification they’d accept instead
Third: Perfect is the enemy of better.
Will this system be perfect? No.
Will everyone trust every judge? No.
Will some people reject any panel that doesn’t confirm their priors? Absolutely.
But here’s the question: Is it better than what we have now?
Right now you have:
Zero transparency about who’s judging
Zero requirement for justification
Zero shared facts
Zero accountability
This gives you:
Full transparency about who’s judging
Required justification for every score
Verifiable facts from disclosed experts
Public accountability
You don’t have to trust the judges. You can see their work and judge for yourself.
That’s the whole point. The transparency is the protection against bias, not the elimination of it.
Some people will still reject it. Some people reject Olympic judges. Some people reject referees. Some people think all experts are corrupt elites.
But for everyone else—for people who want better information to make better choices—this gives you something to work with. Real data, real transparency, real accountability.
Is that perfect? No. Is it infinitely better than blind trust in whoever shouts loudest? Yes.
What About Primaries?
Here’s where it gets really interesting: this format would work just as well—maybe better—within party primaries.
Imagine Republican primary candidates being fact-checked by Republican-leaning experts and judges. Imagine Democratic candidates being scored on accuracy and substance by progressive fact-checkers and judges.
This isn’t about one party having an advantage. This is about voters in both parties getting better information about their own candidates.
Do Republican primary voters want to know which candidate is making accurate claims and which is bullshitting? Yes.
Do Democratic primary voters want to know which candidate has substantive policy positions vs. empty talking points? Yes.
The format serves information quality, not partisan advantage. And both parties’ voters deserve that.
The Meta-Point: Systems Can Be Redesigned
Here’s what matters most about this thought experiment:
Not whether you think 5 judges is the right number, or whether the scoring categories should be different, or whether 3 minutes is enough time to respond.
What matters is this: Did you just spend the last several minutes imagining a better system?
Did you think “yeah, that could work” or “I’d do it differently but the principle is right” or even just “wait, we’re actually allowed to change this?”
Because we are allowed to change the format.
Presidential debates aren’t handed down from on high. They’re not in the Constitution. They’re just... a thing we do, the way we’ve always done it, because no one’s seriously tried to redesign them.
But debates are designed artifacts. Someone made choices about the format. And those choices produce predictable outcomes—specifically, the outcomes we all agree are terrible.
We can make different choices. We can design systems that produce better outcomes.
What Else Could We Redesign?
If we can reimagine presidential debates with built-in accuracy filters and real-time scoring, what else becomes possible?
Congressional hearings with fact-checking built into the process?
Public comment periods with verification systems?
Committee testimony with coherence scoring?
Town halls with engagement metrics?
Once you start seeing political discourse as a designed system rather than an unchangeable reality, the possibilities multiply.
This is what structural thinking looks like in practice. Not just diagnosing what’s broken. Not just complaining about the outcomes. But actually engineering better systems.
The Ask
If you’ve made it this far, you probably agree that presidential debates could be better. Maybe you’d design the system differently than I would. Maybe you think we need 8 judges instead of 5, or different scoring categories, or a different format entirely.
That’s perfect. That means you’re thinking like a systems designer, not a helpless spectator.
The point of this piece isn’t to convince you that this is the right answer. It’s to convince you that answers exist. That we don’t have to accept broken systems just because they’ve always been broken. That structural change is possible.
If you believe that—if you believe debates could be better, even if you’d do it differently—then share this.
Not because you agree with every detail of my scoring system. But because you agree with the premise that underlies everything we do at Statecraft:
We don’t have to live with systems that don’t work. We can build better ones.
Let’s start with debates. And then let’s keep going.
What other political institutions do you think could benefit from this kind of redesign? Drop a comment—I’d love to hear your thoughts.
And if you’re interested in more structural thinking about how to fix broken systems, subscribe to The Statecraft Blueprint. We’re working on consciousness-raising, one system at a time.